Modelling audio signal using visual features
This is a draft of first experiment done on partially reconstructing audio waveform that can capture distinct motion patterns occuring in a video such as hits, collision, throw, etc.
Motivation: We have videos and their corresponding audio stream. Can we exploit it to obtain better features? Self-supervised learning?
Dataset
I used the 19/02/2018 snapshot of Something-Something dataset from internal data factory of 20bn, since the released versions don’t contain audio streams
The data is then filtered using only the classes containing distinct sounds such as hit, collide, drop, etc. for the model to learn the change in sound signal using visual features.
SOUND CLASSES:
1. Hitting [something] with [something]
2. Throwing [something] against [something]
3. Throwing [something] onto a surface
4. Dropping [something] onto [something]
5. Dropping [something] into [something]
6. Dropping [something] behind [something]
7. Dropping [something] in front of [something]
8. [Something] colliding with [something] and both are being deflected
9. [Something] being deflected from [something]
10. [Something] colliding with [something] and both come to a halt
11. Poking a stack of [something] so the stack collapses
12. Moving [something] and [something] so they collide with each other
Following is the number of samples in train and validation splits:
Train split
- Original number in the snapshot = 253,663
- After filtering videos using sound classes = 13,825
- After removing faulty videos = 12,991
Validation split
- Original number in the snapshot = 31,579
- After filtering videos using sound classes = 1807
- After removing faulty videos = 1708
Note: Here faulty videos refer to videos containing no or corrupt audio stream
Method
Preprocessing
Took the audio waveform’s first channel and applied the following transformations:
For example, take the video with label - Hitting [something] with [something]

with duration = 4.25 sec, and with the sampling rate = 44100, the audio waveform looks like,
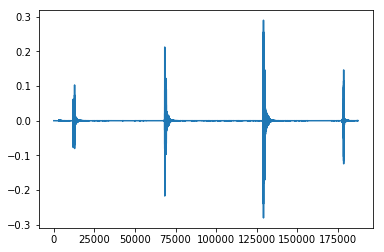
Note: The last tick in the waveform is not a hit but a camera click sound!
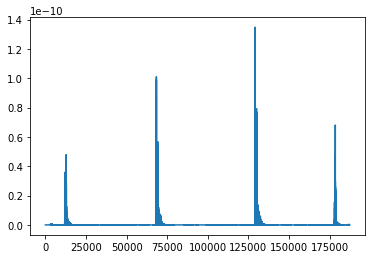
- Scale the 16-bit integers in the waveform to a real value between -1 and 1 using torchaudio’s Scale(), and took the magnitude of each point
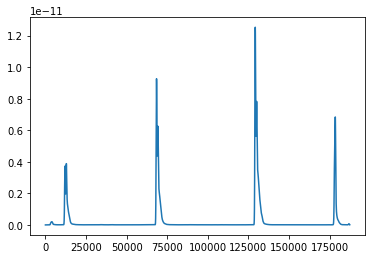
- Smooth the signal using a Gaussian distibution with
mean=0andsigma=200
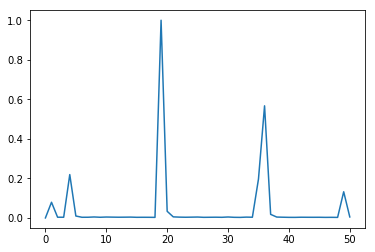
- Downsample the waveform (drastically!) to frame rate of 12 (similar to videos), and scale the signal to
[0,1], to obtain the final waveform:
Model
I took a model pre-trained model on something-something-v2 [1] using the code in the baseline repo [2], which takes:
Input video of shape: [batch_size, 3, num_frames, H, W], where
num_frames = 48
H = W = 224
Output features of shape: [batch_size, 512, 48, 7, 7]
Reshaped to: [batch_size, 48, 512x7x7]
I added 2-layered LSTM to take the signal and output:
Output shape after LSTM layers: [batch_size, 48, 512]
I applied a 3-layered fully-connected NN to convert the 512 dimensional features to size 1:
Output shape after FC layers: [batch_size, 48]
The output is passed though a sigmoid layer to threshold values between [0,1] and then binary cross-entropy loss function is used to regress the values with the processed audio waveform.
The idea is to generate the audio waveform samples corresponding to each frame feature in the video (here num_frames = 48).
Evaluation
From validation set (of ~1700 samples), I randomly picked 100 samples and manually classfied the predictions into three categories - good(1), not_so_good(0), bad(-1).
| Class label | Total samples | Total score |
|---|---|---|
| Hitting [something] with [something] | 16 | 9(1) + 5(0) + 2(-1) = 7 |
| Throwing [something] against [something] | 9 | 7(1) + 2(0) = 7 |
| Throwing [something] onto a surface | 7 | 5(1) + 1(0) + 1(-1) = 4 |
| Dropping [something] onto [something] | 12 | 9(1) + 1(0) + 2(-1) = 7 |
| Dropping [something] into [something] | 12 | 9(1)+ 1(0) + 2(-1) = 7 |
| Dropping [something] behind [something] | 10 | 7(1) + 3(-1) = 4 |
| Dropping [something] in front of [something] | 5 | 4(1) + 1(-1) = 3 |
| [Something] colliding with [something] and both are being deflected | 9 | 7(1) + 2(-1) = 5 |
| [Something] being deflected from [something] | 8 | 7(1) + 1(-1) = 6 |
| [Something] colliding with [something] and both come to a halt | 6 | 5(1) + 1(0) = 5 |
| Poking a stack of [something] so the stack collapses | - | - |
| Moving [something] and [something] so they collide with each other | 6 | 5(1) + 1(0) = 5 |
| TOTAL | 100 | 60 |
Given the scoring method (of assigning values in {-1, 0, 1}), the expected value of a random algorithm will be 0. The best and worst case will give 1 and -1 respectively. The above analysis suggests a score of 0.6 (= 60/100).
Sample Predictions (good=1)
Most of random noise in the audio signal is caused by background music, people talking, object specific movement(e.g. car wheels), camera clicks, etc.
Id: 85210; Label: Dropping something into something
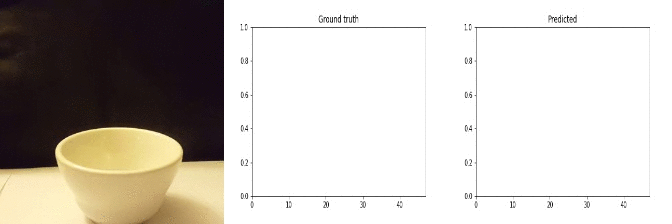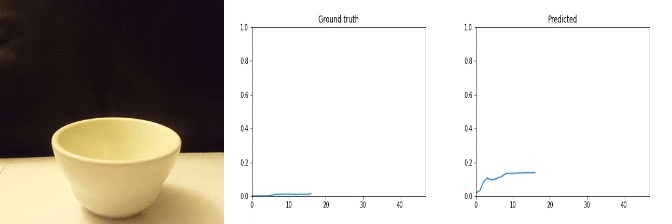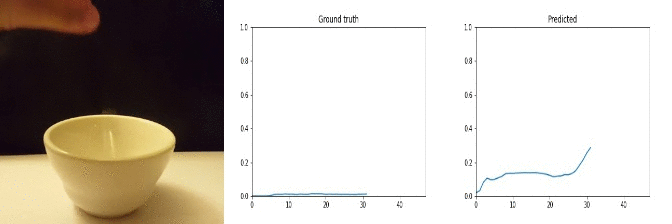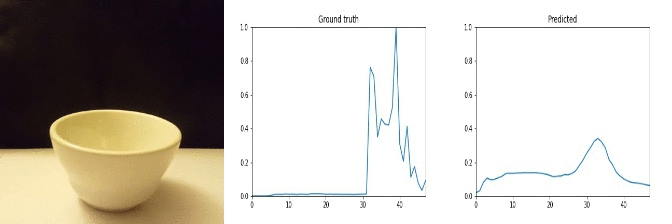
Id: 1712533; Label: Something colliding with something and both are being deflected
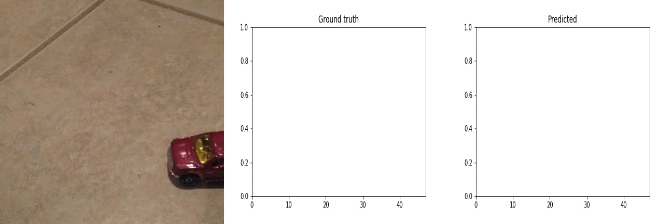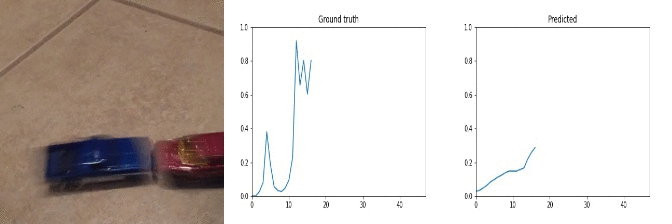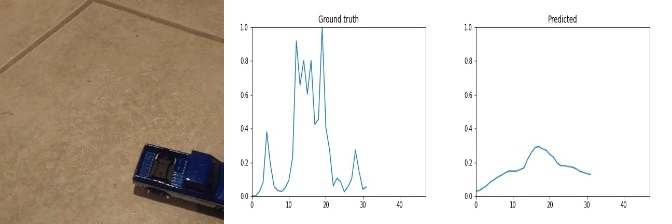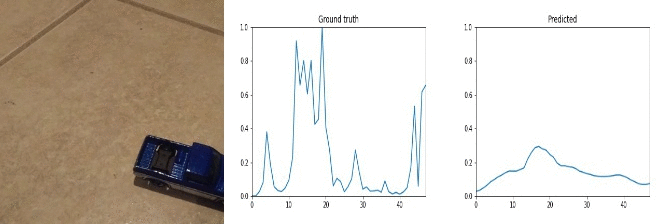
Id: 1068329; Label: Dropping something behind something
peak near end
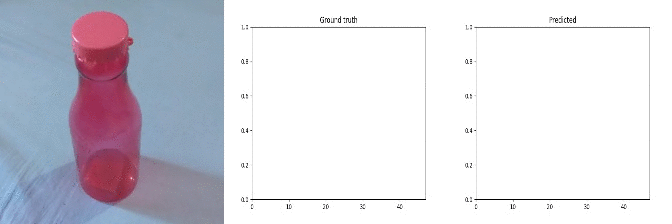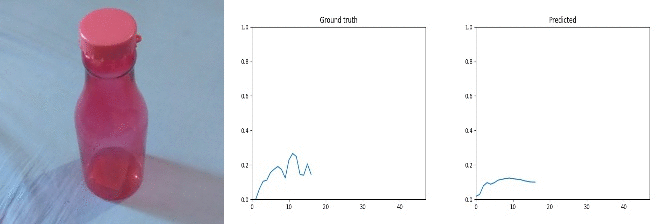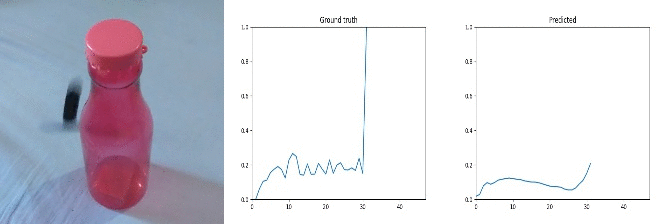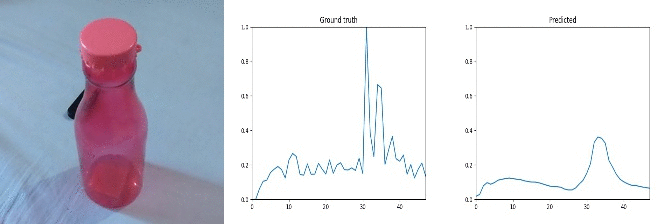
Id: 755333; Label: Something colliding with something and both are being deflected
50 cents to 2 euros!
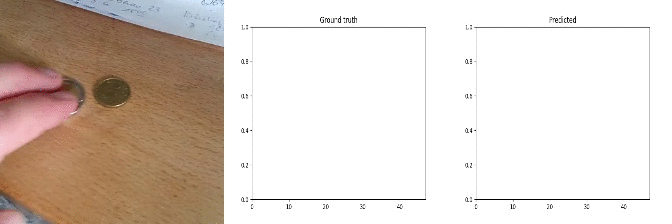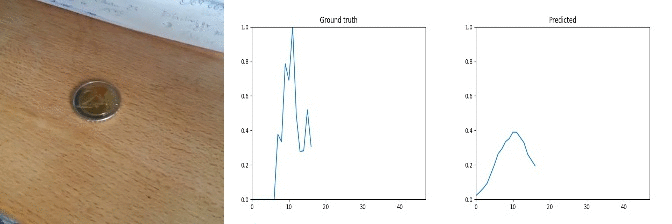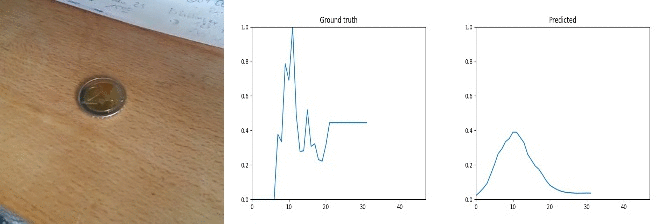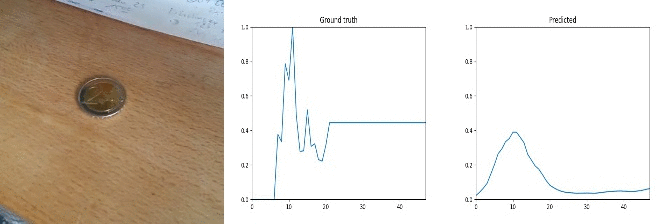
Id: 1767982; Label: Dropping something into something
Note: camera sound click at the end in the ground truth
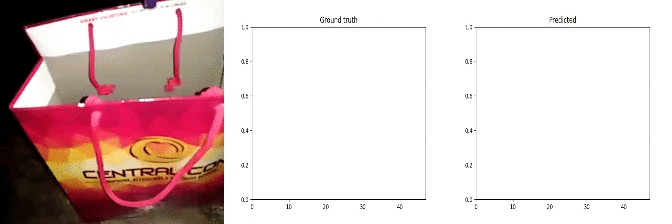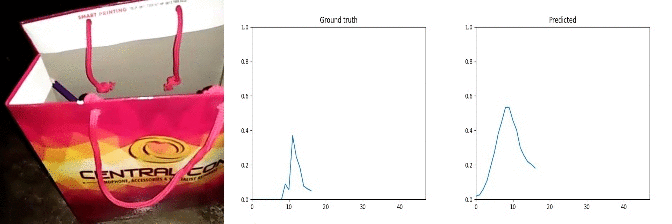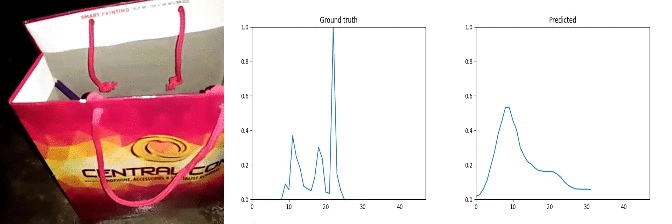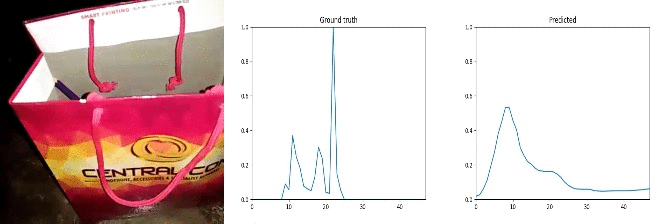
Id: 1057884; Label: Hitting something with something
Note: random noise in ground truth
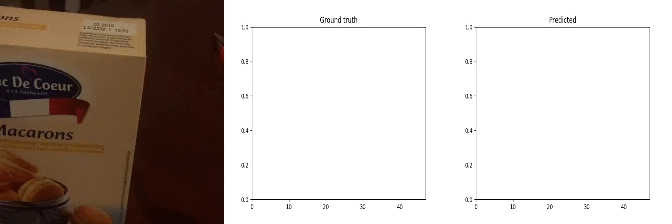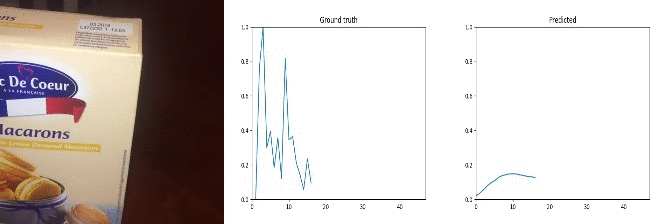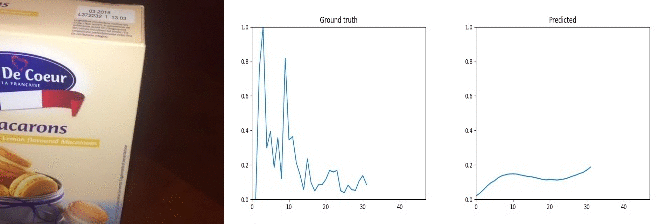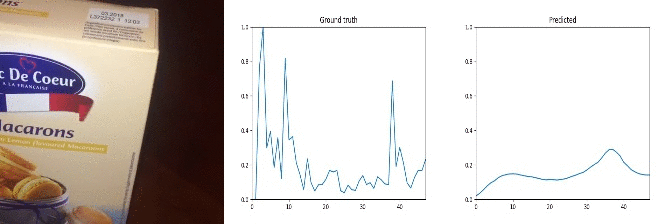
Id: 909860; Label: Moving something and something so they collide with each other
Note: random noise in ground truth
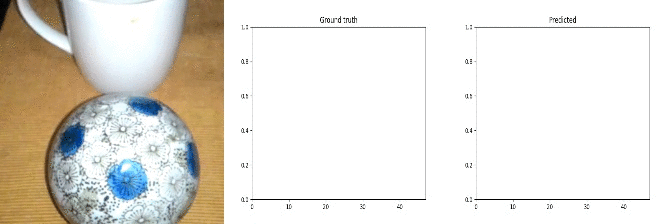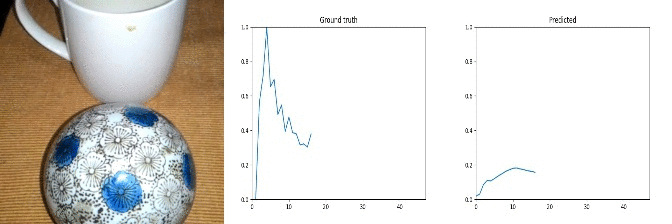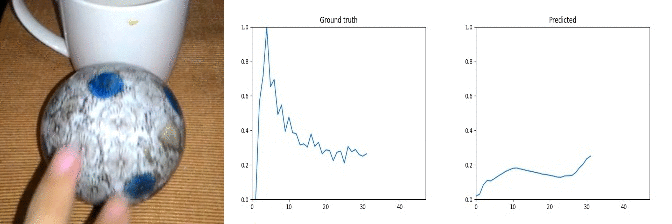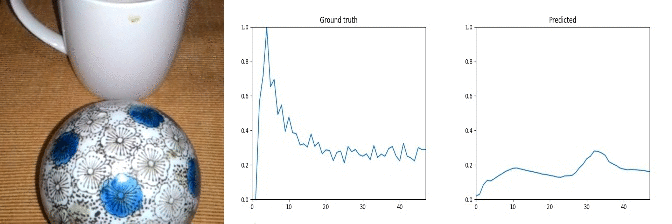
Id: 90395: Label: Something being deflected from something
Note: random noise in ground truth
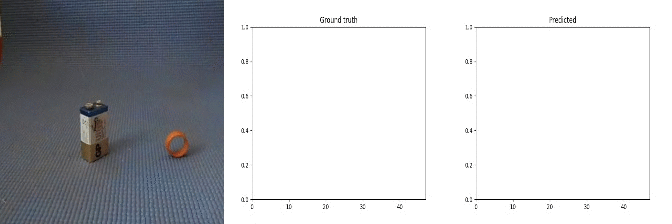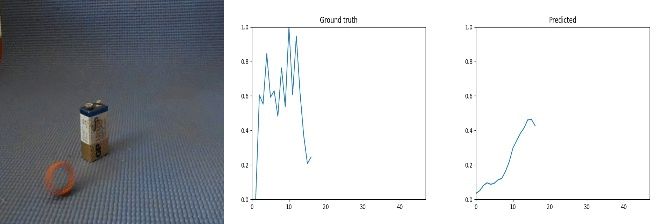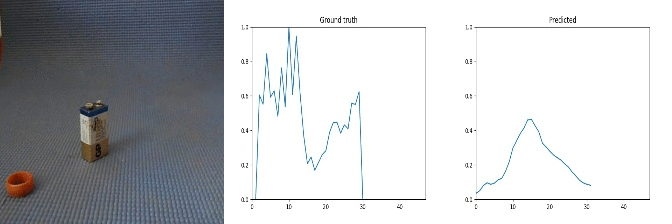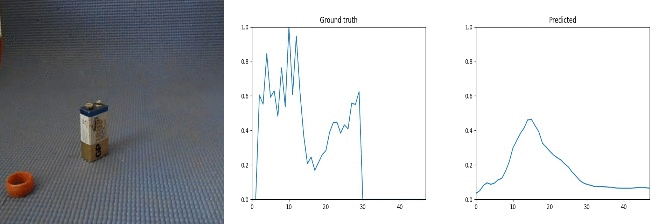
Sample Predictions (not_so_good=0)
Id: 53381; Label: Moving something and something so they collide with each other
multiple hits
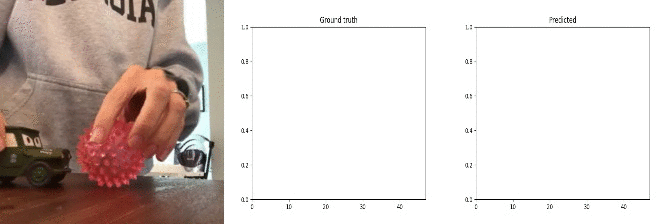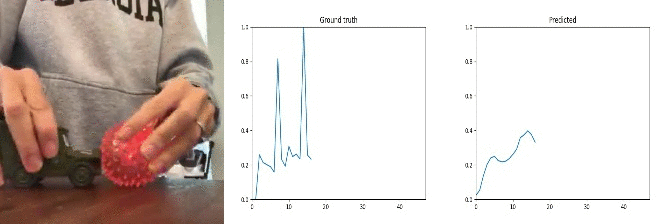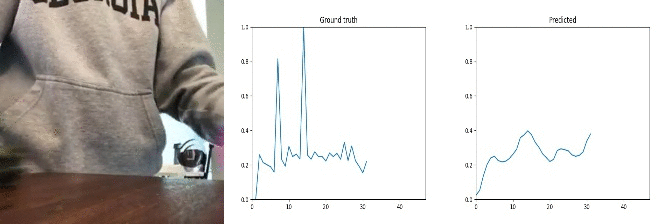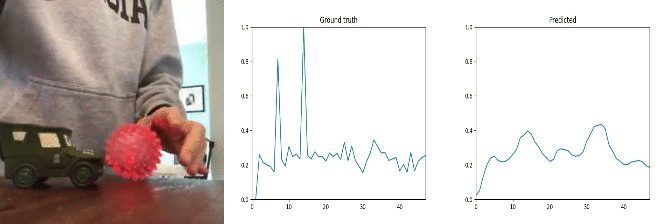
Id: 89109; Label: Dropping something into something
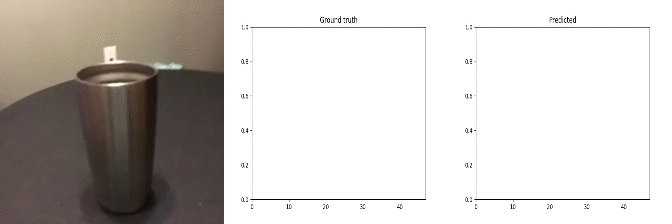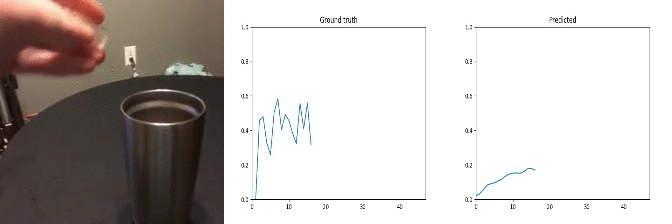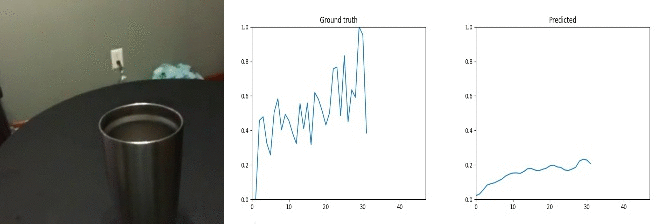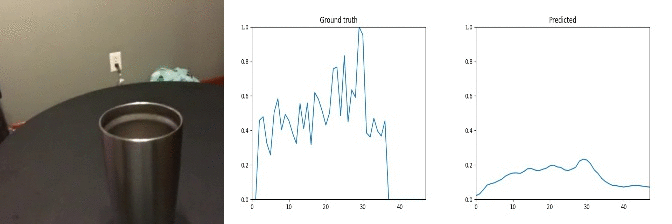
Id: 1070404; Label: Hitting something with something
multiple peaks not recognised
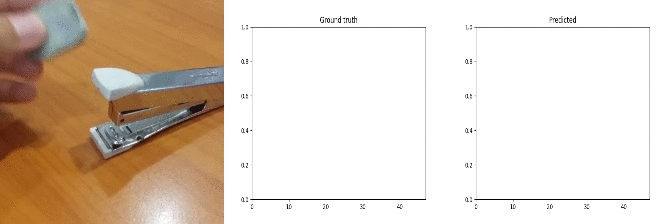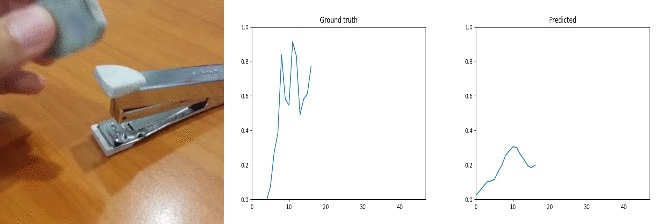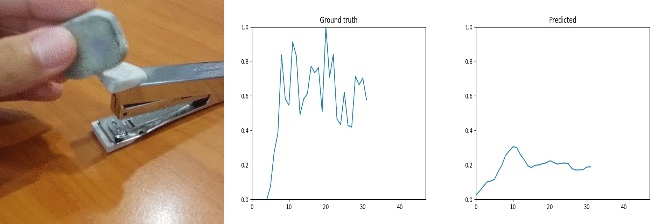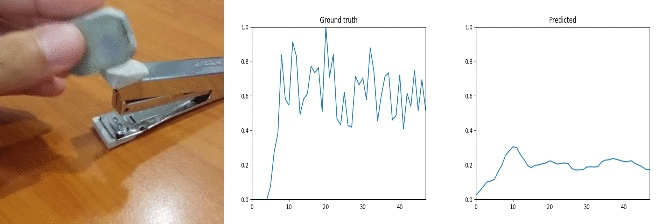
Sample Predictions (bad=-1)
Id: 1439494; Label: Dropping something behind something
faulty
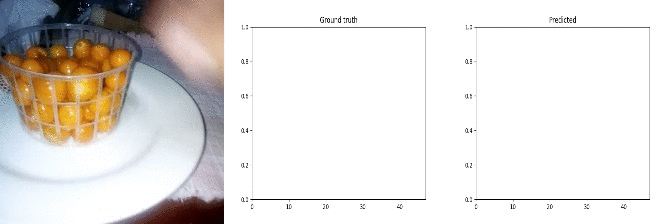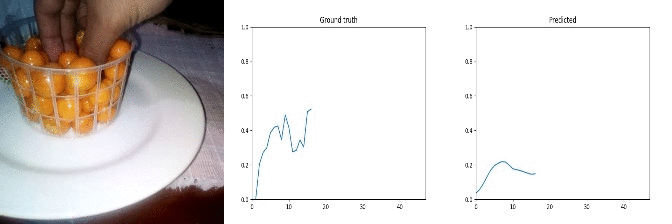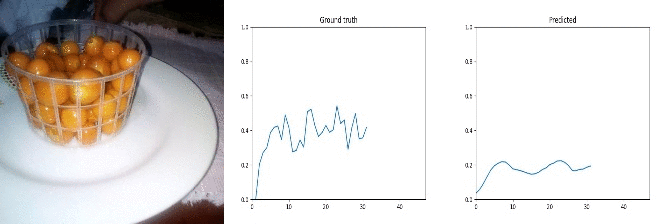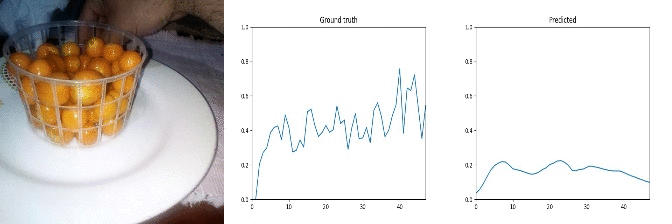
Id: 1625641; Label: Dropping something behind something
wasted!
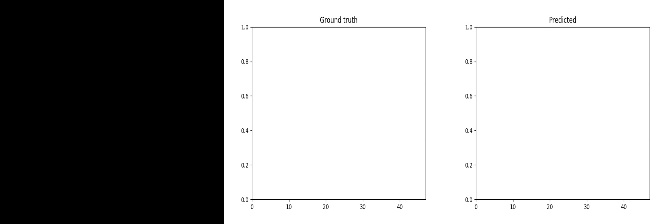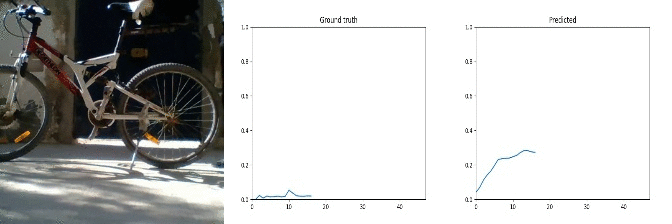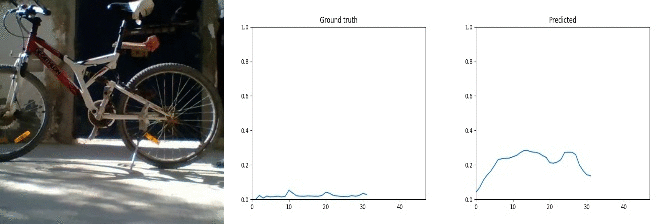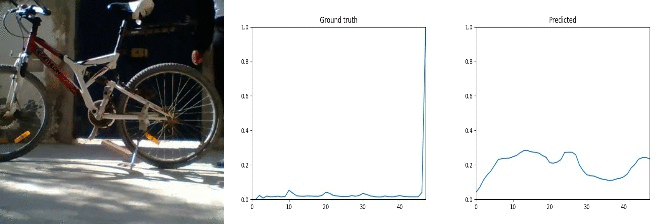
Id: 1368947; Label: Dropping something in front of something
wasted!
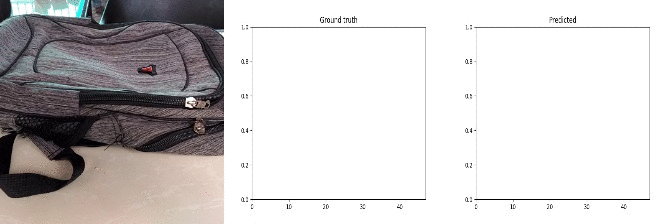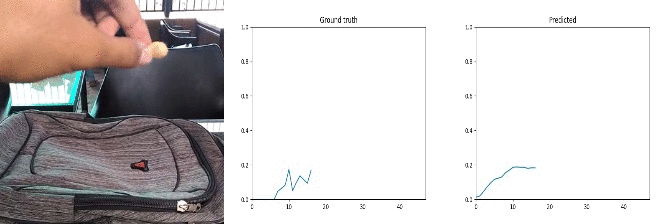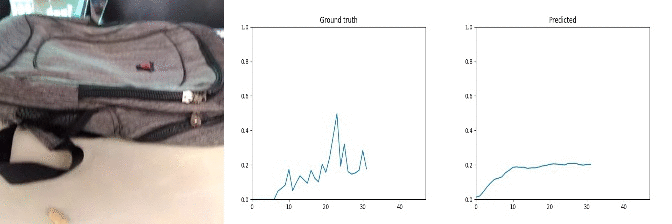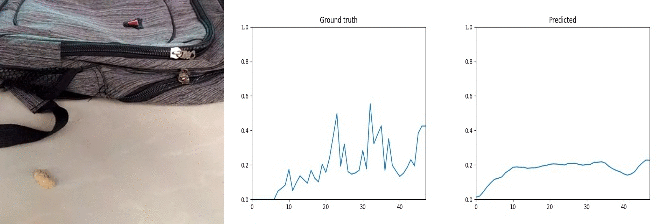
Id: 96318; Label: Dropping something into something
wasted!
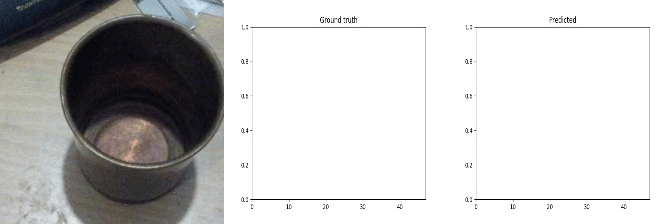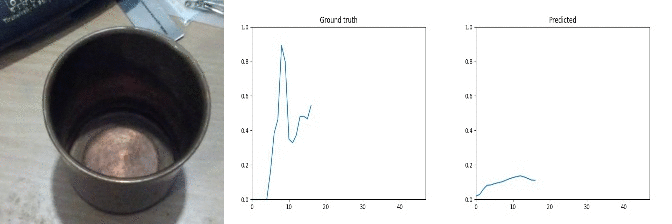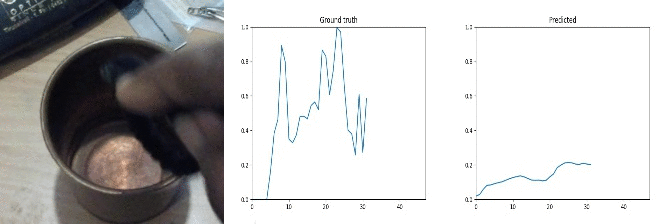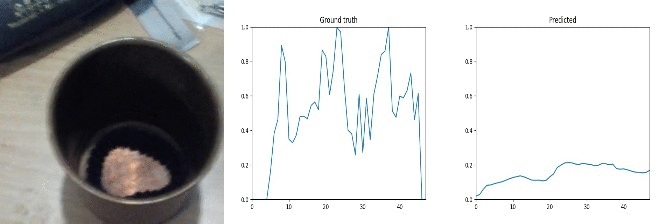
Id: 666725; Label: Dropping something onto something
faulty recording
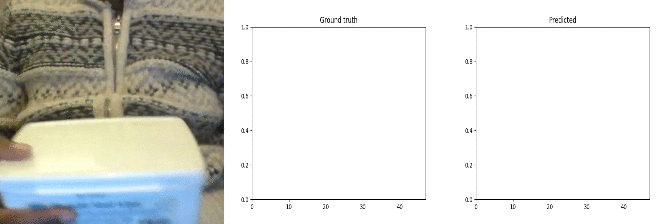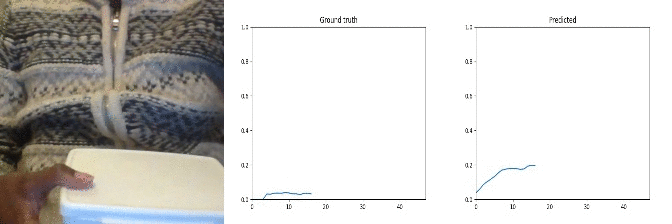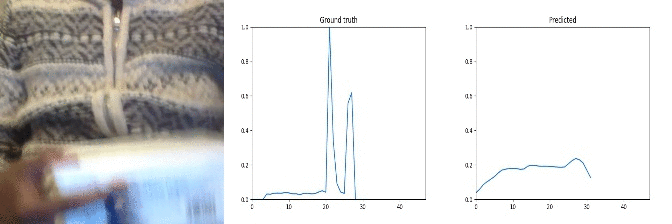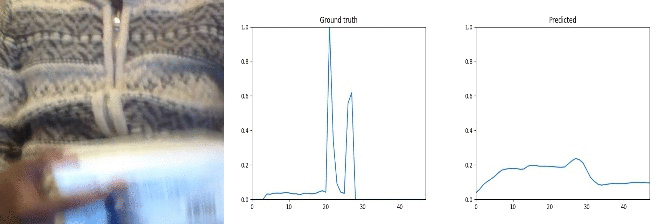
Id: 33045; Label: Dropping something onto something
why 2 peaks?
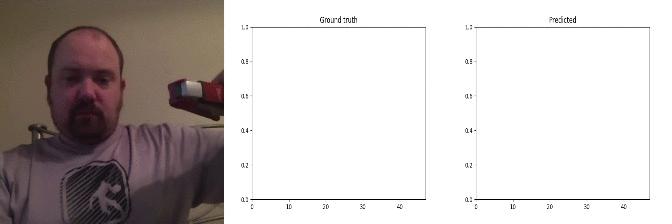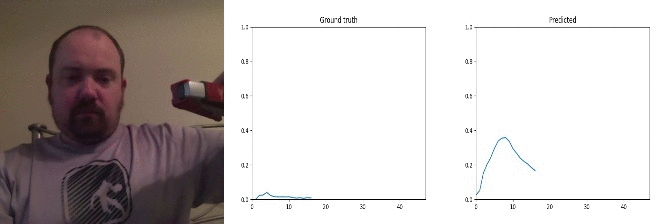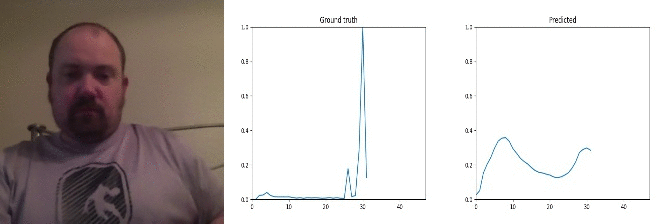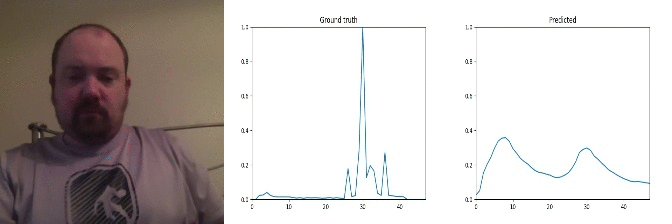
Id: 1843956; Label: Hitting something with something
remote controller button press - no discernible action!
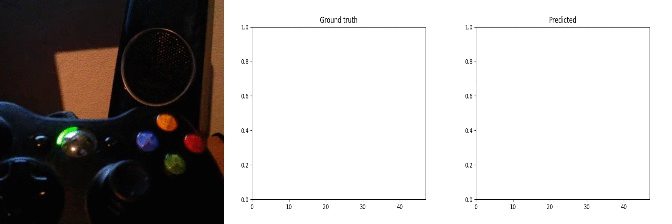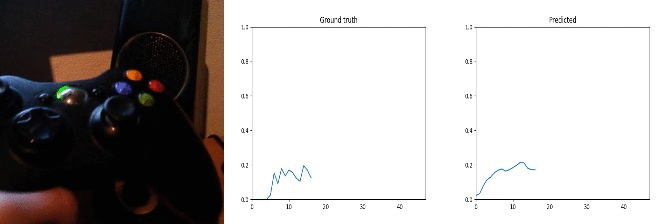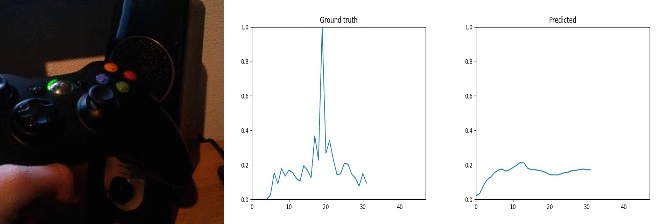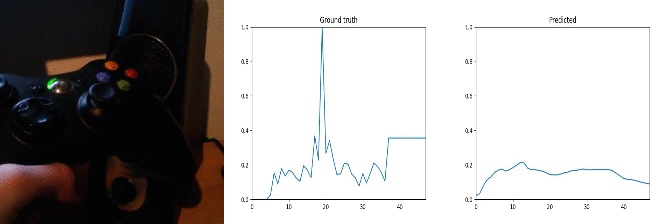
Id: 1442357; Label: Hitting something with something
wasted!
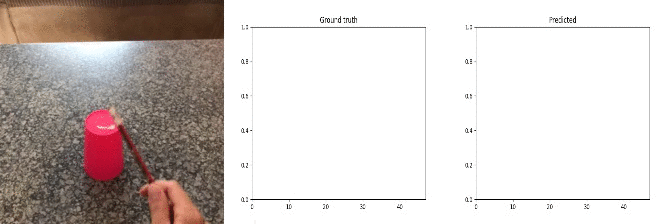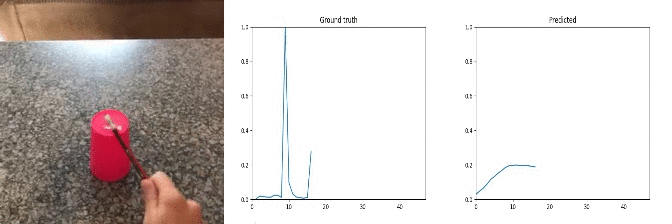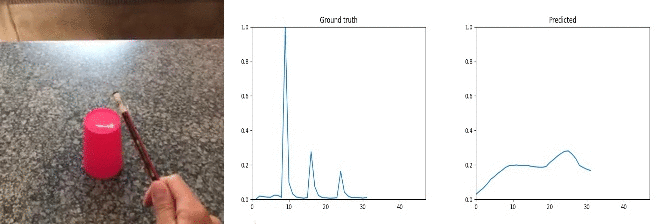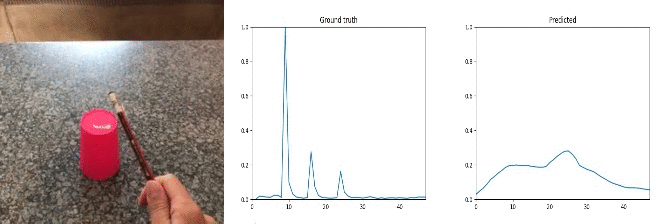
Conclusion
This is a first attempt to explore whether self-supervised learning can be leveraged to improve generalisation capabity of model in the case of something-something dataset. The future work will be to potentially use this as an auxillary task!
Please comment or provide any feedback for the approach taken. Thanks for reading :)
References
[1] https://www.twentybn.com/datasets/something-something/v2
[2] https://github.com/TwentyBN/something-something-v2-baseline