Visual explanation for video recognition
This post describes how temporally-sensitive saliency maps can be obtained for deep networks designed for video recognition. It is evident from the previous works [2, 3, 4] that saliency maps helps visualize why a model produced a given prediction and can uncover artifacts in the data and point towards a better architecture.
Task: To recognize human actions in videos from our recently released dataset which requires fine-grained understanding of the concepts [1]. The dataset dubbed as “Something-Something” consists of ~100,000 videos across 174 categories containing concepts such as dropping, picking, pushing etc.
Few Examples from the dataset
 |
 |
 |
 |
|---|---|---|---|
| Picking [something] up | Pretending to put [something] onto [something] |
Pushing [something] so that it falls off the table |
Putting [something] into [something] |
Visualization Technique used: Grad-CAM
Grad-CAM or Gradient-weighted Class Activation Mapping, proposed by [4], allows us to obtain localization map for any target class. It involves,
- Calculating gradients of a class logit w.r.t. to activation maps corresponding to the final convolutional layer.
- Taking weighted average of these activation maps by using the gradients as weights.
- Finally, applying ReLU to highlight regions that positvely correlates with the class chosen.
- Projecting the obtained result back to the input space in the form of heatmaps (coarse localization maps).
Please refer [4] for more details.
Architecture details
For videos, a natural choice is to consider a video as a sequence of image frames and extend 2D-CNN filters in time domain to obtain 3D-CNN, which has been proved useful for video recognition tasks [5, 6]. We inflated ImageNet pre-trained ResNet-50 filters in time domain, following similar lines of work done by [6] for Inception-v1 and trained the resulting model on our dataset, choosing a subset of 40-classes as described in [1].
The dimensions of the final convolutional layer’s activations is 16x2048x7x7, with input of the dimensions 16x3x224x224, following the convention of (number of image frames x num channels x width x height). We chose a uniform kernel size of 3 in time domain with padding and stride of 1. This results in activation maps having the same time dimension as the input but not uncorrelated in time.
The 40-classes subset of the data contains 53,267 total samples with splits made in the 8:1:1 ratio [1]. The test-set accuracy of the above architecture is 51.1%, which is ~15% better than what is reported in our paper at 36.2%.
Temporal localization maps
Using the above trained model, we took some random samples and visualized them using Grad-CAM [4,7]. The data is sampled at 4fps, and with a clip size of 16 frames (see above), the videos represent at most 4 secs of activity.
The examples below shows the original video alongwith a heatmap overlayed version of it (red – intense). Also, the true label and top-2 predictions are shown beside each example.
Few positive ones
| # | Original and heatmap’ed GIF | Label |
|---|---|---|
| 1 |  |
True Putting [something] Predictions 1. Putting [something] :– 0.84 2. Dropping [something] :– 0.10 |
| 2 |  |
True Tearing [something] Predictions 1. Tearing [something] :– 0.99 2. Stacking [number of] [something] :– 0.00 |
| 3 |  |
True Uncovering [something] Predictions 1. Uncovering [something] :– 0.99 2. Opening [something] :– 0.00 |
| 4 |  |
True Closing [something] Predictions 1. Closing [something] :– 0.96 2. Opening [something] :– 0.02 |
| 5 |  |
True Pushing [something] so that it slightly moves Predictions 1. Pushing [something] so that it slightly moves :– 0.43 2. Pretending to take [something] from [somewhere] :– 0.20 |
| 6 |  |
True Approaching [something] with your camera Predictions 1. Approaching [something] with your camera :– 0.26 2. Dropping [something] :– 0.15 |
| 7 | 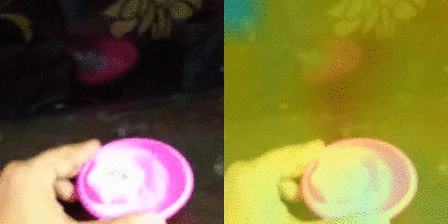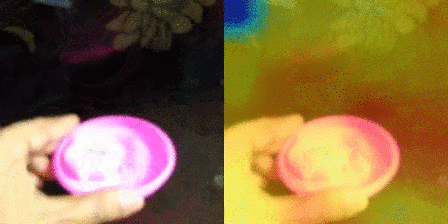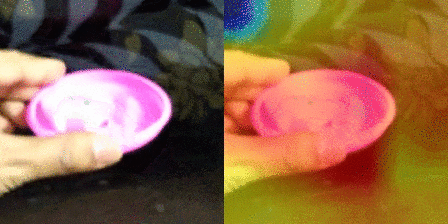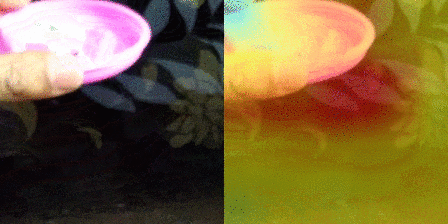 |
True Picking [something] up Predictions 1. Picking [something] up :– 0.99 2. Putting [something] :– 0.00 |
Few medium ones
| # | Original and heatmap’ed GIF | Label |
|---|---|---|
| 1 |  |
True Picking [something] up Predictions 1. Turning the camera downwards while filming [something] :– 0.67 2. Picking [something] up :– 0.10 |
| 2 |  |
True Holding [something] Predictions 1. Turning the camera left while filming [something] :– 0.21 2. Turning the camera right while filming [something] :– 0.21 |
| 3 |  |
True Throwing [something] against [something] Predictions 1. Dropping [something] :– 0.97 2. Throwing [something] against [something] :– 0.01 |
| 4 |  |
True Picking [something] up Predictions 1. Pushing [something] with [something] :– 0.34 2. Picking [something] up :– 0.25 |
Few negative ones
| # | Original and heatmap’ed GIF | Label |
|---|---|---|
| 1 |  |
True Holding [something] Predictions 1. Turning [something] upside down :– 0.67 2. Turning the camera left while filming [something] :– 0.07 |
| 2 |  |
True Pushing [something] so that it slightly moves Predictions 1. Dropping [something] :– 0.50 2. Picking [something] up :– 0.11 |
| 3 |  |
True Picking [something] up Predictions 1. Pushing [something] with [something] :– 0.19 2. Picking [something] up :– 0.15 |
Discussion
Looking carefully, the above examples conveys that the model, in most cases, has learned to follow the object of interest over time and we’ll follow up on this work in the future.
At TwentyBN, with the help of our proprietary data platform, we’re collecting videos describing fine-grained concepts in the world with the aim to enable a human-like visual understanding of the world. Recently, we released two large-scale video datasets (256,591 labeled videos), and we believe our efforts in this direction will help the community to take on further challenges.
References
[1] Goyal et al. ‘The “something something” video database for learning and evaluating visual common sense.’ arXiv preprint arXiv:1706.04261 (2017). In ICCV 2017. [To appear]
[2] Zeiler, Matthew D., and Rob Fergus. “Visualizing and understanding convolutional networks.” European conference on computer vision. Springer, Cham, 2014.
[3] B. Zhou, A. Khosla, L. A., A. Oliva, and A. Torralba. Learning Deep Features for Discriminative Localization. In CVPR, 2016.
[4] Selvaraju, Ramprasaath R., et al. “Grad-cam: Why did you say that? visual explanations from deep networks via gradient-based localization.” arXiv preprint arXiv:1610.02391 (2016). In ICCV 2017. [To appear]
[5] D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri, Learning Spatiotemporal Features with 3D Convolutional Networks, ICCV 2015.
[6] Carreira, Joao, and Andrew Zisserman. “Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset.” arXiv preprint arXiv:1705.07750 (2017).
[7] https://github.com/jacobgil/pytorch-grad-cam